
How Twitter can fix misinformation, without fact-checking

On Nov 15, Nathan from ZeitgeistPM suggested an “accuracy” feature for Twitter:


Nathan’s solution strikes me as incredibly close to helping Twitter fix misinformation, increase revenue, and more.
One slight tweak — I propose users rate each Tweet on a scale of 0-100 to express disagreement or agreement, instead of “This is True”/”This is False.” Nathan’s highlighted yellow box would therefore say “65% agrees with the public / 78% agrees with those you follow.”
I’ll explain why that’s important in a minute.
Meanwhile, here’s a brief snapshot of how far Twitter could take this:
Benefits
The opinions of 100 people you trust, will soon outweigh the opinion of 1 institution you don’t trust. Disruptive information will gain legitimacy in the time it takes for a tweet to go viral. Instead of waiting 18 months for Washington Post to admit COVID might have come from a lab leak, you’ll be able to point to a list of friends or influencers who are 90% confident about this within hours.
Feedback loop between “who you trust” and “what they said when it counted.” A public database of confidence ratings 0-100 make it easy to see who was insightful and who was just following trends. Imagine querying the database — “Who rated [IMPORTANT THING] above [90] at [EARLY TIME]?” Every important matter of subjective judgment will filter out the next class of thought leaders. Remember when Balaji called COVID? Imagine having a list of people who called COVID, and being able to see their collective opinion about any new topic, at a glance.
Infinite analytics layer. You could filter the ratings database to answer questions like these:
What do [user]’s followers believe most strongly?
What do {users who rated [TweetA] above [90] before [DATE]} think about [TweetB]?
What do my followers and [user]’s followers most agree on?
What users most closely agree with me about everything I’ve rated?
Easily build a dating app: Which {users who rated [Tweet “I am single and female”] above [90]} most closely agree with me about everything I’ve rated?
Advanced ad targeting. A database of personal opinion enables unprecedented precision for ad targeting:
Show my ad only to {users who rated [Tweet A] above [90]}
Show my ad only to {users who rated [Tweet A] AND [Tweet B] above [90]}
etc.
Persuasion markets. Rating data can be used to settle prediction markets about matters of opinion.
Will [members of this Twitter list] collectively rate [Tweet: “Ivermectin prevents COVID”] above [90%] by [January 1, 2024]?
Will {users who rated [TweetA] above [90] before [DATE]} collectively rate [Tweet: “Ivermectin prevents COVID”] above [90%] by [January 1, 2024]?
etc. Want to make a bet? Decide on a “jury” of users, either manually or using some kind of parameters, and let their ratings adjudicate.
I’d probably pay $8/month for the privilege of rating Tweets and using all these filters…
Fix misinformation, without fact-checking
The frame of Agree/Disagree acknowledges that the supply chain of Facts ultimately rests on personal opinions.
This is why, in an age where anyone can find support for a dissenting opinion, the very concept of “facts” is no longer persuasive. Consensus can no longer come from establishing facts. No matter how “true” the facts are, this strategy will only erode trust.
However, consensus might yet come from trusting trustworthy individuals. This is why a database of personal opinions might succeed where other solutions have failed — optimizing for trustworthiness intervenes deeper in the epistemology stack than solutions based on verification of facts, and requires no censorship.
Solving for trust is also far simpler:
When we solve for trustworthiness instead of factualness, the amount of things we need to agree on is reduced from ∞ to 1.
Instead of needing to agree on criteria for verifiability (infinite debate over philosophy) and whether they’ve been met (infinite debate over evidentiary and methodological minutiae), we only need to agree on whether we trust the person whose opinion it is.
Then, by iterating personally and collectively on the question of who deserves our trust, we can discover who earns trust across demographics, take their opinions as “fact” for practical purposes, and replace them in real-time if they lose our trust.
This isn’t an unfamiliar process. It’s what we’re already doing inside our heads all the time! “Balaji was right” about COVID, so we trust him more in the future. Maybe someday he’ll be wrong about something and we’ll trust him less. I’m only suggesting that what we do privately and informally in our heads, we also do publicly and formally in code.
If it works, the era of allowing the same institutions to lead populations into wars and pandemics on false premises decade after decade, will not only be over — it will be replaced.
In short: Trust is upstream of Facts. Solve for trust directly, and let facts solve themselves indirectly.
Next steps
A browser extension could serve as a prototype, and probably be built in only a few weeks.
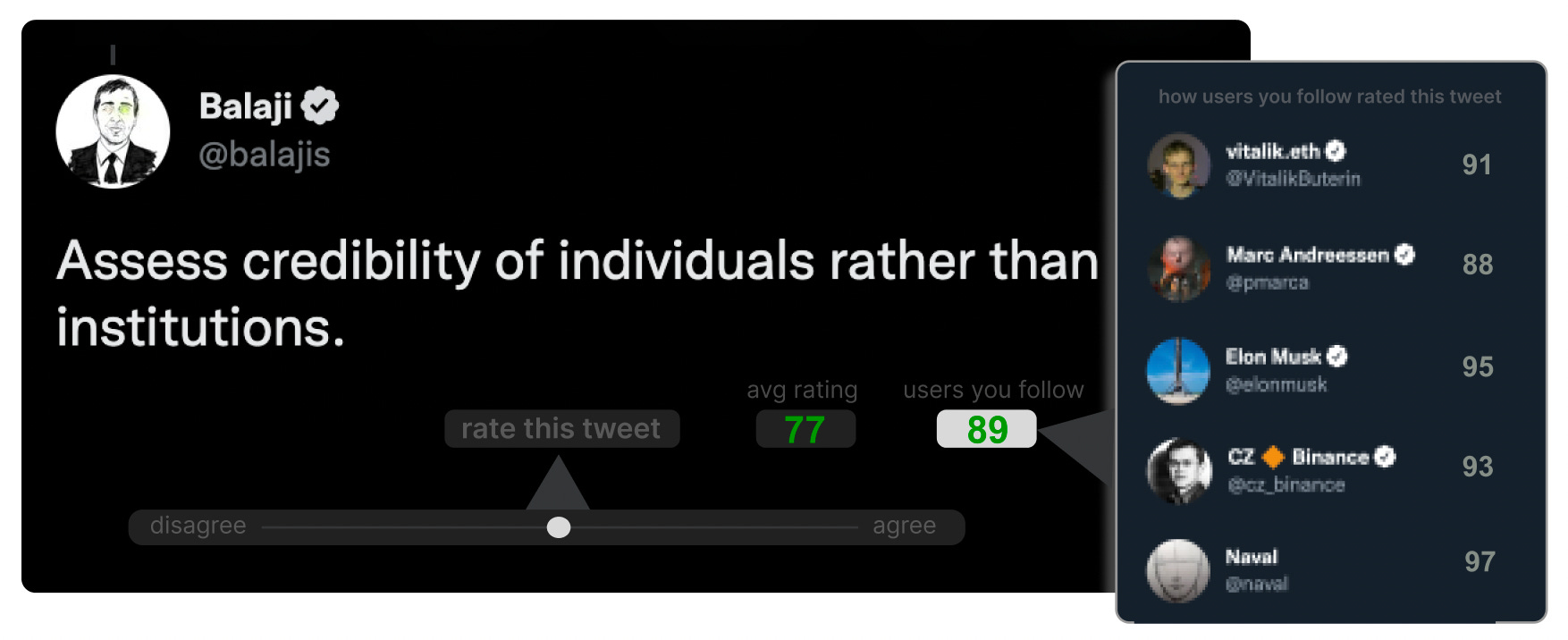
If you’d like to build this Chrome/Brave browser extension as an official Ideamarket product in exchange for 100,000 IMO (~$1,500 at today’s prices), respond to this email.
I’m happy to assist anyone who wants to try building something like this, Ideamarket-related or not. 😊 (Maybe Farcaster?)
Cheers,
—Mike
PS — Please share this post. If a solution like this becomes popular, it will probably be good for Ideamarket. Ideamarket does all of the above — only on-chain, with financial incentives built-in, and organized as a knowledge graph:
To the extent the “opinion database” idea catches on in Web2, so may the demand for its equivalent in web3.